
FastSLAM
Software Engineering Practice
This project is still under active work. Check out our Github Repo and check back for more updates!
I took a seminar class during my first semester at Brown called “Coordinated Mobile Robotics”, in which I got the chance to read a decent amount of papers. This class was also taught by my thesis advisor, so the seminar was a perfect introduction to the type of research her lab was conducting. One of my favorite paper from that class was on SLAM, specifically on using ultra-wideband range measurement between robots as a new type of pose-graph constraint for the SLAM back-end optimization. I thought that paper was very well-executed from idea to implementation.
SLAM (Simultaneous Localization And Mapping) remained a vague problem on my mind until I started my Master’s at Brown. However, there were plenty of lead-ups during my previous projects that guided me eventually to SLAM. During my previous Pi Car project, I thought about using landmark localization in the navigation system of the Pi Car. We ran out of time before I could explore the idea, so I was eager to learn more. During my internship at iRobot, I interacted with the team that developed the visual-SLAM solution for Roomba robots for my tickets. I didn’t get the chance to contribute since I was occupied with other tickets.
So here comes this nice project to get my hands dirty: implementing a crude SLAM algorithm based on a 2001 paper: “FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem”, written by Michael Montemerlo, Sebastian Thrun, Daphne Koller, and Ben Wegbreit [1]. Thrun was one of the authors of Probabilistic Robotics, so this project turned out to be very fitting. Graph-based SLAM was first formulated in 1999 and didn’t gain popularity till later on, but this paper used a very early-stage factored graph approach. I thought it will serve as a nice base for future projects.
 The paper behind this project
The paper behind this projectAnother good news is I won’t be working alone. The initial idea of this project came from a PhD student I met when taking the seminar. We also have a fellow CS Master’s student, whom we also met during the seminar, and two undergrads who were kind enough to help out. Team work is always good in my opinion, but it does come with some challenges. One of them is how to organize and structure our work.
Working in A Software Team
At iRobot I was immersed in a lot of cool “industry” practices I have never seen before in school. My team loosely followed the SCRUM methodologies to structure work. I also had the chance to talk to some project managers and DevOp engineers. By the end of the internship, my horizon was drastically expanded with knowledge on how to work with teams and maintain a shared repository.
When this project rolled around, I wasn’t going to pass on the opportunity of practicing what I preach, so I offered to set up and maintain the necessary infrastructures for teamwork.
Introducing Kanban
At iRobot I followed SCRUM, but I thought it didn’t really fit the style of development we do in school. SCRUM organizes work via sprints, which are hard to do since we are full-time students, and this is an outside-of-school project. I therefore turned to SCRUM’s sibling: Kanban.
Kanban is more fitting in our context for a couple of reasons. First, the goal of Kanban is to maximize velocity (the speed of a ticket moving from left to right on the Kanban board). There is no fixed time-frame compared to SCRUM, so it is perfect for students since our schedules are dictated by school work. Second, Kanban offers a lot of visibility through the board. In the case where a teammate needs to put their work on hold and focus on school work for a week, other team members can identify the missing teammate’s task and address it accordingly.
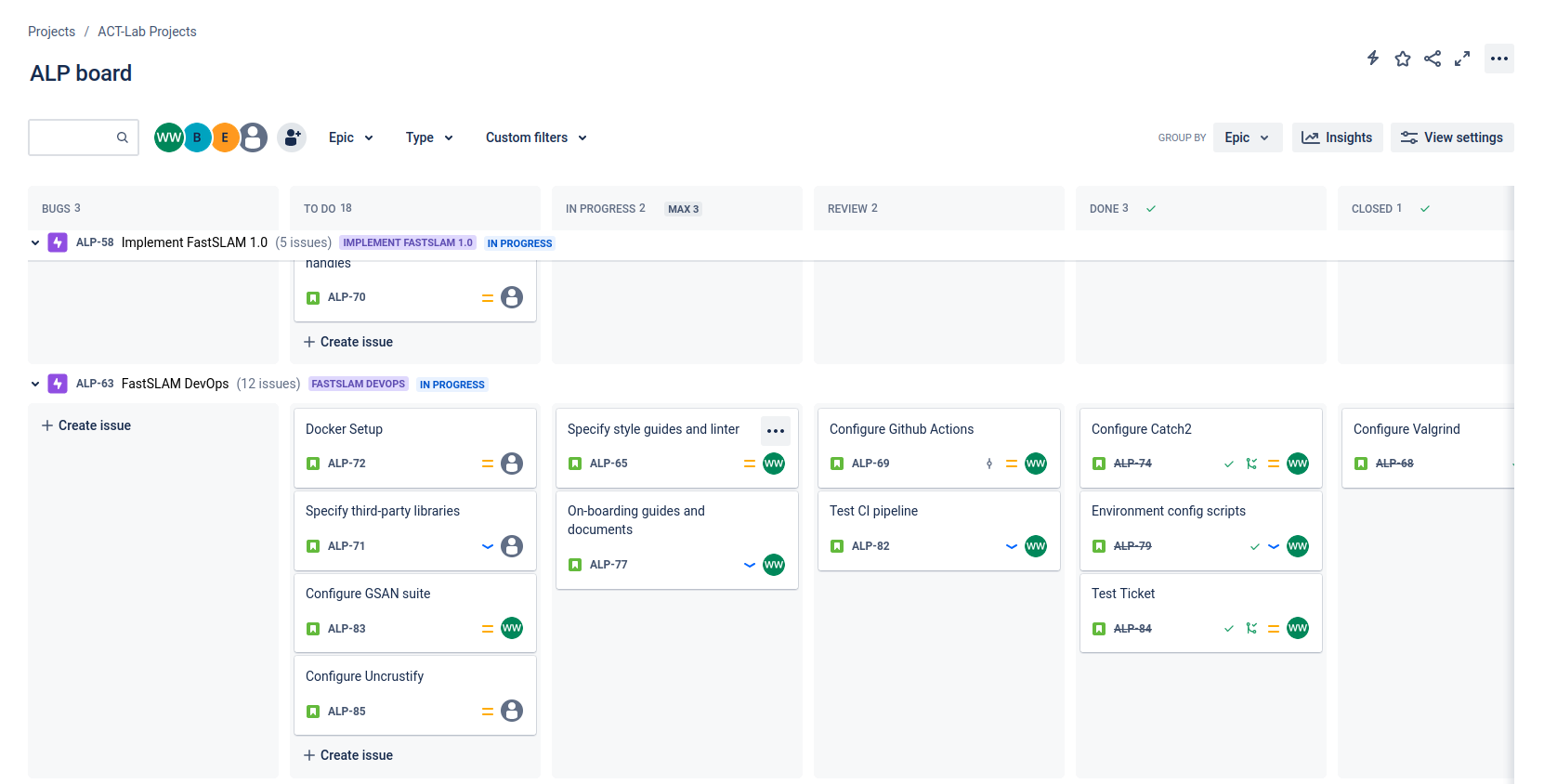
Jira is familiar territory for me after my internship
I used Jira at iRobot, so I chose Jira for our team.
We also decided to write our tickets descriptively and include a “done when” statement. The statement makes the task more defined. This especially benefits our younger team members who can learn by doing concrete tasks.
Branching Model
From the start, we thought it was a good idea to introduce version control and maintain a well-defined workflow. We decided to follow a classic branching model with dev and main as our default branches. dev is where all developers will base their feature branches off from, and main will serve as the stable branch for robot testing. All branches are guarded, so changes has to go through the Pull-Request (PR) process to make into dev, then main. The CI pipeline runs weekly on dev, and if the code on dev passes all automated checks, it will merge into main.
DevOps and CI
Besides using Git to interact with the repository, I wanted to incorporate some Continuous Integration (CI) elements to our work to really smooth out the experience. I identified a couple of necessary elements to include in our CI pipeline:
- Unit testing: this is a must have. Also for Test-Driven Development (TDD)
- Documentation generation: this is a school project that may one day turn into a teaching tool, so we wanted to have some sort of doc-string based tool to generate documentation.
- Style and format checks: it’s good to maintain readable and organized code
- Sanitizers: C++ is not memory safe, and we are bound to run into memory problems as learners of this language. Why not add some extra safety?
For the above four elements, we chose Catch2 for unit tests, Doxygen bound with Github Pages for automated documentation, Clang-tidy for style and format checks, and lastly, Google Sanitizers for memory and thread safety. We have already incorporated Catch2 and Doxygen at the time of writing. The last two elements are currently in the works.
All the tools mentioned above are wrapped up nicely with a Github Actions job. The job gets triggered when:
- A Pull-Request (PR) is approved
- A PR is merged into the
devbranch - Every Monday night on
devandmainbefore our team meeting on the next day
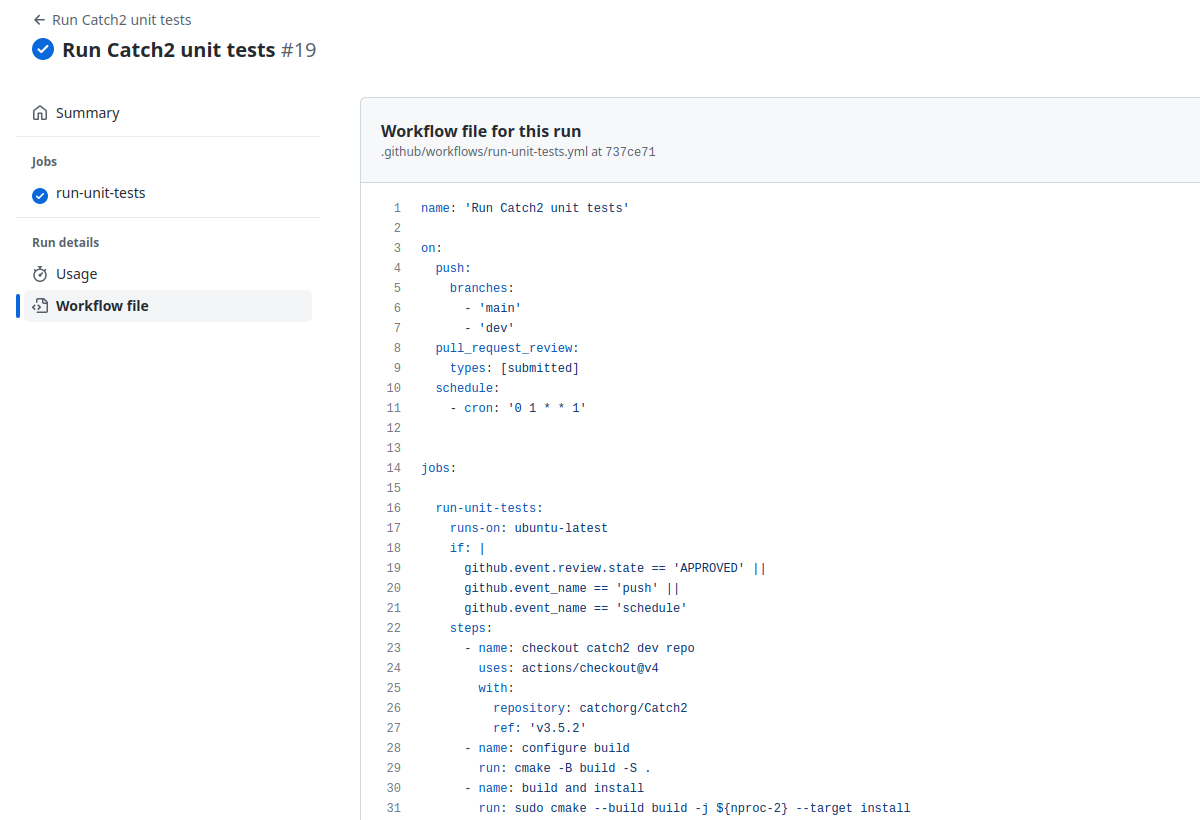
![]() We set up the CI pipeline to run automatic unit tests under certain conditions. The process also produce a unit test status badge
We set up the CI pipeline to run automatic unit tests under certain conditions. The process also produce a unit test status badge
We consider changes merged into the main branch to be generally stable, so we also base our Doxygen generation off of main. The Github Actions job will automatically build the documentation website and deploy it Github pages.
I also drafted up some documents for interacting with the CI pipeline. So far I think everyone is enjoying it. I think this is a worthy investment, and time will tell how much it pays off.
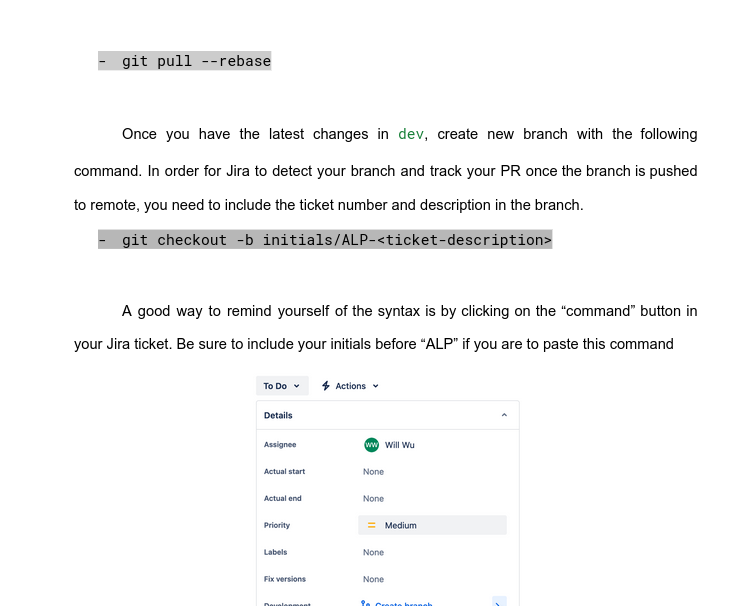
The onboarding document for younger members on the team
Future Work
Once we have the four tools above integrated into our tool chain, I think we would have reached a good place to focus more on the development of the actual algorithm. The FastSLAM algorithm itself is sensor and motion agnostic, but I still expect there to be some transition work to put on hardware (sensor firmware, etc).
One of the things we would love to have is to build a CD pipeline that deploys to a simulator or a robot. From the deployments, we would be able to conduct further qualitative integration tests for our algorithm. I think this will be really worthwhile to do in the future, since it can also serve as the infrastructure for the research group to develop other algorithms on.
The FastSLAM Algorithm
This section is till being actively worked on. More work is coming soon!